Is cloud-based Matillion ETL the answer for Redshift/S3 integration?
Adam Stewart
/ 2016-05-18Several years ago, one of our project teams was tasked with building out a full EDW in Amazon Redshift. The solution needed to source from multiple subject areas including sales, supply chain, operations, and customer demographics. We truly had a great amount of variety, velocity, and volume requirements. The sales source was configured to publish large sets of flat files to Amazon S3 throughout the day and large reconciliation batches overnight. Seeing that multiple different types of SCD’s would need to be maintained, the lack of native S3 connectivity became a significant roadblock in the workflow.
Our team set out to find, recommend, and implement an enterprise level ETL platform to handle the requirements and were unsuccessful at finding any packaged solution that supported S3 and Amazon Redshift. We settled on a traditional tool and set out to build an orchestration framework. Our solution involved a custom java program to download/upload data to/from S3 and calling a lot of command line packages to perform the loads to Redshift. The design ultimately worked but there was little-to-no reusability and the flexibility of dealing with data on the fly was missing.
As luck would have it, a potential solution to all of issues mentioned above hit the Amazon marketplace shortly after the project’s completion, Matillion’s ETL for Redshift. I was tasked with populating one of the bigger dimension tables, Employee, using Matillion and seeing if any of the hang-ups they experienced during the project development were still present. Here’s a breakdown of how I accomplished the task.
- First of all, launching the environment was a breeze. Using the Amazon Marketplace, you just click a few buttons and your environment is online. No downloading and installing software, no massive configurations. It just works.
- Next, I started my job with connecting to S3 to grab the raw employee data. In the original architecture, the flat files were actually DBF files and stored in an archive in S3. With some handy Python scripting, we extract the files, merge them and convert to CSV. For simplicity sake, I started my task working directly with the final CSV files, but Matillion can easily be configured to add these steps to the workflow. Matillion has really made the interaction with S3 completely seamless. Just input your credentials and the bucket location and all of the other customization options make sure your data ends up in the right place in the right format, every time.
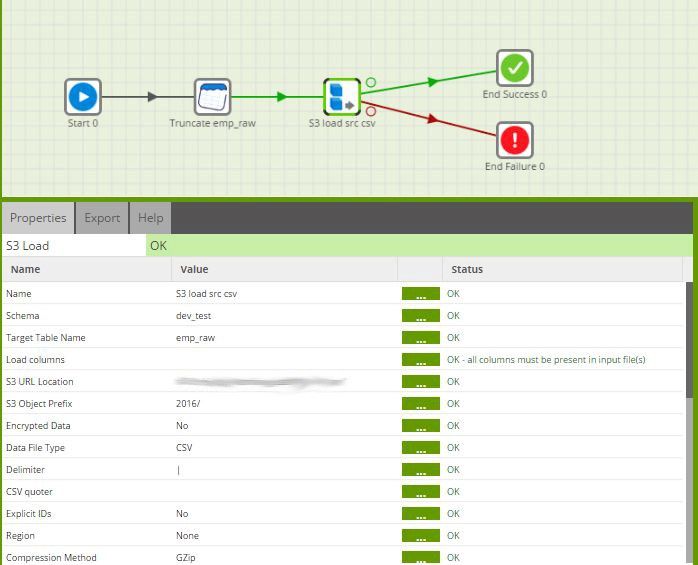
- Next, we need to join the raw employee data together with other necessary dimension tables and load the resulting dataset into a staging table that mirrors the actual employee dimension in structure. This was important in order to use Matillion’s Detect Changes component effectively.

- Next, I was able to detect all “new” records in the staging data using Matillion’s Detect Changes component.

As long as the key columns matched between the two tables, all you have to do is tell Matillion what fields you want to compare and it takes care of the rest. The component marks each row with an indicator column that will tell you whether it is Changed (C), Identical (I), Deleted (D), or New (N). You can even verify the results in real time without running the entire job!

For this step, I filtered the resulting dataset down to the N’s and inserted those rows straight into the employee dimension table as “Current”.
- To accomplish the Type 2 requirement a series of steps were required to maintain a “Current” as well as keep a running history of any attribute changes within the employee dimension.
- Tag the “Current” version of the record to be updated as “Pending”
- Insert a new version of the record with the updated info “Current”
- Expire the “Pending” record by updating the row expiration date and setting its row status to “Expired”

- Here’s the final orchestration that will accomplish all of the steps outlined above.

While the framework we built using a traditional ETL tool works well and accomplished our goal, it took a lot of time and iterations to get it right. Apples to apples, we estimated that Matillion would have saved us about 30 days against our 90-day project plan!
In short, Matillion is definitely going to be a go-to tool when dealing with anything in the ETL/AWS realm. It’s still in its beginning stages and already showing the maturity and robustness of some of the major players in the ETL space. Add-on the seamless Redshift integration and the fact that they’re adding native connector components daily, and you can only be excited for what is to come in the future from Matillion ETL.
If you’d like to give Matillion a try, head over to the AWS Marketplace and check out their free 14-day trial. Or give us a shout and we can walk you through the process or give you a demo.
While we’re confident you could pick it up as fast as we did due to a great knowledge base and video library, iOLAP also offers a Matillion ETL Quick Strike. With this offering, our team helps you get your first subject area online in no time. From Redshift cluster configuration, data modeling, to the Matillion ETL build, we ensure you have the right framework in place to scale your Redshift journey.
For more information, drop us a line at info@iolap.com or contact us at (888) 346-5553.