Data Quality using Azure DevOps Pipelines
Austin Chambers, Ajay Kalyan, Andrea Arapovic
/ 2022-03-10Introduction
Ensuring the quality of data has become a critical component in all data engineering projects. Quality data instills confidence in business decision makers and builds trust across teams. Tools existing in the marketplace range in complexity, ease of use, maturity and implementation timelines and is typically outlined for future phases for projects. Introducing a process to validate data on a consistent basis early in a project can differentiate your team.
Problem
Early on in a recent project, we noticed that data in the lower environments were not indicative of the data conditions in the Production environment. There was a significant amount of edge cases that needed addressing. A robust process was needed to quickly define and identify potential issues. so that we could understand the conditions and continually improve the quality of data to end users.
Solution
This diagram shows the logic behind our implemented solution:

ETL jobs were executed through Tidal. A successful data load triggered an Azure DevOps Pipeline run via the REST API. The pipeline was responsible for checking out a repository, dynamically compiling test cases from the checked-out repository, executing test cases, and publishing test results for each run. Upon completion, failure notifications were sent to a Microsoft Teams channel.
Simplicity and minimal development were key decision drivers. Additional benefits include:
-
Flexibility - test cases can be added /modified with a commit to the repository
-
Serverless Architecture – a runtime environment was instantiated on demand based on the Azure Pipeline YAML file
-
Leveraging built in Azure DevOps functionality – in particular, taking advantage of the compatibility of Azure Repo’s, Pipelines, built in test plan dashboarding and Microsoft Teams
What does that look like?
We created a repository using Azure Repos and attached it to an Azure Pipeline that required a manual trigger. A python script scans through a folder and starts to identify all .sql files.
Inside those SQL files, we can define some metadata associated with the test case example:
-
Name – The developer of the test case was responsible for providing a descriptive name that would be visible on the Pipeline test dashboard
-
Type – Although not used initially, this could be expanded to categorize tests example, smoke, regression, etc. to run only partial set of tests during a run.
-
Expected Result – All of our test cases were set up to expect a count of 0 but configurable for future test cases if needed
-
Sql – The sql statement to run in a readable format

To be able to use those SQL test cases, we need to set up Azure Pipeline. Tasks included:
1. Installing any dependencies that are needed from a Python perspective

2. Compiling and executing the validation – scanning through all .sql files, generating and executing the test cases using pytest, and outputting results in a junit format

In this step, a validation script (validation.py) is triggered. In the script we designed a function that compiles all test cases by going through and scanning the repository for all SQL files and pulling the actual SQL statements and metadata into a python dictionary.

PyTest is the base framework used and it is a key piece in identifying all running tests and outputting each one of them. Test cases can be parameterized using a python array using the pytest.mark.parametrize function.

3. Publishing test case results to Azure Pipelines – gives a consolidated view of the test case results and also a historical view of all test case executions
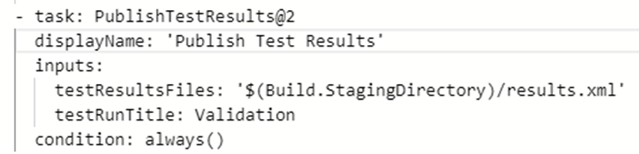
The published results are exposed via a dashboard for each Azure Pipeline run.

4. Notifications via Microsoft Teams – Lastly, notifications of the status of a run are sent to a Microsoft Team channel using the available connector. In our case only failures were configured to notify to minimize noise.
What about adding new test cases?
When adding new test cases, a new .sql file must be added to the repository. That SQL file needs to be formatted as all others, which means, you copy one previous file, change the metadata information (name, type, expected result) and edit the SQL statement with what you need the test to do.
Conclusion
The solution outlined above led to proactively addressing data quality issues prior to ingestion in the production environment. The team was able to creatively re-envision a common process needed on all data integration/engineering projects and take advantage of the toolsets available to software engineering and apply to data.
iOLAP offers a wide range of different services in Data & Analytics, as well as partner with Microsoft.