ML Model Deployment with Kubernetes and Go Language
Milan Blazevic
/ 2023-11-20One of the challenges when building a machine learning platform, is how to enable the data scientists to dynamically deploy their models into a production environment- so they can rapidly update, optimize, and monitor models- enhancing agility, efficiency, and responsiveness to changing needs and data. This challenge is something that is being solved using MLOps.
Machine learning models are deployed to solve specific problems or provide value in various applications, such as healthcare, finance, recommendation systems, and autonomous vehicles. In these scenarios, model performance directly impacts real-world outcomes.
In healthcare, for example, accurate and performant diagnosis models are crucial for life-or-death situations. Consumer-facing applications, such as recommendation systems, significantly impact user experience – subpar performance leads to frustration, while high performance enhances satisfaction and loyalty. Safety-critical applications, like autonomous vehicles, demand models with extremely high performance to prevent catastrophic consequences. In resource-constrained environments like edge devices, optimizing model performance for efficiency without sacrificing accuracy is essential. The scale and volume of data also plays a role, with high-traffic platforms requiring real-time predictions with low latency.
Recognizing when performance is critical involves considering real-world consequences, user experience, safety, resource constraints, and compliance requirements. In the evolving field of machine learning, balancing trade-offs and optimizing performance is crucial for successful deployment, ensuring AI systems deliver intended value and impact.
MLOps (Machine Learning Operations) is a collaborative set of practices that integrates machine learning, data engineering, and DevOps principles to streamline and automate the development, deployment, and maintenance of machine learning models in production environments. Applying these practices increases the quality, simplifies the management process, and automates the deployment of Machine Learning and Deep Learning models in large-scale production environments. MLOps enhances operational efficiency, reduces time-to-market, and ensures consistent and reliable performance of machine learning models, thereby driving better decision-making and competitive advantage.
Challenge
The primary challenge is finding a solution for enabling data scientists to dynamically deploy models in a production environment. This involves considering architectural choices that address performance challenges, scalability, and customization beyond standard cloud service offerings. Balancing cost-effectiveness with overall performance is crucial, given that relying on specific vendor platforms can be financially demanding. Another key consideration is ensuring flexibility for a potential switch between cloud providers to avoid extensive refactoring.
Solution
To address the challenges and facilitate the dynamic deployment of machine learning models, a specialized ML platform was developed using Kubernetes. This platform was initially deployed on AWS, but its design allows for flexibility in deployment across various cloud platforms or even on-premises setups, thanks to Kubernetes' cloud-agnostic nature. The Elastic Kubernetes Service (EKS) was utilized for deploying the Kubernetes Cluster, enabling the creation of diverse services tailored to specific needs within that environment.
When addressing performance challenges, it’s important to choose the right tool for the job, so selecting a programming language was a particularly intriguing aspect of the project. Initially, Python with FastAPI was employed, driven by the appeal of its rapid development capabilities. However, as challenges related to suboptimal performance emerged, a thoughtful shift to the Go language was initiated. In this transition, Go's efficiency and concurrent programming features were harnessed. Complementing this shift, Fiber, a web framework tailored for Go, was adopted, aiming to amplify the overall performance and responsiveness of the Services. This strategic adjustment not only addressed the initial performance concerns but also reflected the commitment to optimizing the system for long-term reliability and scalability.
How the Platform Works?

Kubernetes orchestrates containerized applications across a cluster of machines, managing aspects like deployment, scaling, and operations, to ensure efficient and reliable system performance.
In this setup, the Kubernetes cluster resides on AWS, where each node aligns with an EC2 instance. Within each node, numerous deployments can be hosted. To introduce a new microservice to the Kubernetes environment, a Kubernetes Deployment is created, functioning as an abstraction layer responsible for overseeing the application's lifecycle across these nodes. When managing services, there are four abstraction levels to consider: a container, a pod, a replica set, and a deployment.
To develop a microservice, a Docker image containing the application code must be built together with a Pod in Kubernetes, which can hold multiple containers (typically one main and optional sidecar containers). Replica Sets are used to maintain multiple identical Pod replicas, to ensure high availability and scalability. Adding a further level of abstraction, Deployments are created for each service; Kubernetes then automatically handles the underlying tasks, including creating the required Pods and containers within them.
To make the microservice accessible to users, a Service and Ingress must be set up in Kubernetes. Ingress acts as a traffic routing mechanism based on request paths, where an Ingress controller like Nginx is utilized, functioning as a reverse proxy. Deploying a new Ingress controller automatically initiates the creation of a Load Balancer in the background. Incoming traffic first reaches this Load Balancer, which then directs it to one of the nodes where the Nginx Deployment determines the appropriate route and service to use, according to the defined Ingress rules.
This outlines the platform's initial functionality. Now, let's delve into the details of model deployment, the construction of services and how end users can leverage them.
ML Model Deployment

The approach centers around providing data scientists with a tailored Application Programming Interface (API) designed to streamline the deployment process. Via this API, they can effortlessly submit requests for deploying their machine learning models to the platform. These requests include details of the specific model to be deployed and a comprehensive image containing all required logic and dependencies. Furthermore, they can specify resource requirements like memory, CPU, and GPU usage, and other deployment options like canary releases, among various other parameters.
Solution
In this process, data scientists compile all necessary information into a request and submit it to the platform, targeting the Model Deployment Service. This service dynamically provisions Kubernetes resources in response to the request. Specifically, it creates a new Model Inference Service, leveraging the image prepared by the data scientists, and makes this service available to users via Nginx and a Load Balancer. Essentially, the Model Deployment Service uses the provided image to establish a Model Inference API, which exposes the desired models to end users through a REST API interface.
The journey of constructing the Model Deployment Service and choosing the programming language became particularly fascinating when Python with FastAPI was initially opted for. However, faced with suboptimal performance, the decision was made to transition to the Go language and embrace Fiber, a Go-specific web framework, to address these challenges.
Python vs Go Language
The performance of Python and Go Language in the context of ML model deployment was intended to be compared, and the reason for choosing Go is to be demonstrated. Two services were constructed: the first utilizing Python and FastAPI, while the second employing Go and Fiber. The identical functionality of both services involves dynamically provisioning and terminating Kubernetes resources to expose ML models as an API. A direct comparison will be made between the performance of these two services across various categories, encompassing execution time, docker image creation, CPU and memory utilization, dependency compilation, compilation duration, and overall performance.
Execution Time
The comparison of the two algorithm implementations' execution speeds was conducted using Application Performance Monitoring (APM) agents. These agents gathered performance metrics from the services and sent them to an APM Server in our cluster, which then relayed the data to Elasticsearch for visualization using Kibana.
The analysis showed that deploying and destroying machine learning models using the Python-based service took about 1000 milliseconds on average. In stark contrast, the Go-based service achieved much faster performance, with deployments averaging around 150 milliseconds and destructions just 30 milliseconds.
Consequently, the Go Language application was between 6 and 33 times faster than the Python application, depending on the task. Furthermore, the Go web framework Fiber was capable of handling approximately 300,000 requests per second, a significant increase compared to FastAPI's capability of managing only about 200 requests per second.
The Python metrics:

The Golang metrics:

Docker image
In evaluating the complexity of producing Docker images and the size of the generated images for Python and Go applications, a notable difference was observed. Given that the application provides a REST API, it necessitates shipping as a Docker image.
A multi-stage build approach was adopted for creating the Docker image: initially building the app and aggregating data, followed by assembling a "production" image. In this context, Go proved to be exceptionally efficient. The Go compiler was instructed to produce a self-contained binary, which could be packaged in a minimal scratch image, resulting in a final image size of just over 31 MB. In contrast, the Python application's final Docker image was significantly larger, amounting to hundreds of megabytes. This stark difference highlights Go's advantage in terms of both image size and the efficiency of the build process for Dockerized applications.
CPU and memory usage
To compare the CPU and memory usage of Python and Go applications, a Prometheus server was set up to pull metrics from nodes and pods, with Grafana employed for visualizing these metrics. The results showed a significantly higher resource usage for the Python application, with up to 37 times greater CPU usage and up to 4 times more memory consumption compared to the Go (Golang) application. In a production environment, where resource usage directly translates to operational costs, Golang emerges as a much more cost-effective solution due to its substantially lower CPU and memory requirements.
The Python Usage Results:


The Go results:


Dependencies
When developing a service to support ML model deployment, it is common to rely on various libraries, such as ML-specific ones (e.g., TensorFlow, PyTorch) or those for interacting with Kubernetes Clusters and model registry services like MLflow. However, these dependencies often come with their own sets of sub-dependencies, which can sometimes lead to conflicts that must be resolved before building the Docker image. Additionally, if these dependencies are not correctly pinned, they can cause issues in production.
Python applications are particularly prone to breaking in production due to missing runtime dependencies, incorrect or incompatible library versions, or the wrong Python version. In contrast, the Go Language compiles into a single binary, eliminating these types of issues entirely. This characteristic of Go significantly enhances the reliability and stability of the application in production environments, as it is not susceptible to the same dependency-related problems that can plague Python applications.
Compile time and overall experience
The comparison between Go, a compiled language, and interpreted languages like Python isn't direct due to their fundamentally different nature but Go can be more aptly compared with other compiled languages like C or C++.
One notable advantage of Go is that its compilation time is linear with respect to the number of imported packages, as opposed to the exponential compilation time often experienced with C/C++. This means significantly less waiting time during development, particularly after making changes or testing new lines of code, which enhances the efficiency and experience of model deployment.
The design of the Go programming language (Golang) is highly commendable. Its straightforwardness, strong support for concurrency, and enhanced readability form a feature set that is exceptionally attractive. These qualities not only facilitate easier and more efficient coding but also contribute to the overall robustness and maintainability of the applications developed in Go.
Let’s Dig into The Code
The complete application can be accessed at this GitHub repository: https://github.com/iolap-blog/mlops, and an overall walkaround will be provided to enable an understanding of the overall approach taken in this context.
REST API
Here, all necessary modules are imported, and the Kubernetes configuration is set up to enable the utilization of the Kubernetes client for interaction with the Kubernetes Cluster, facilitating the creation, updating, or deletion of resources.
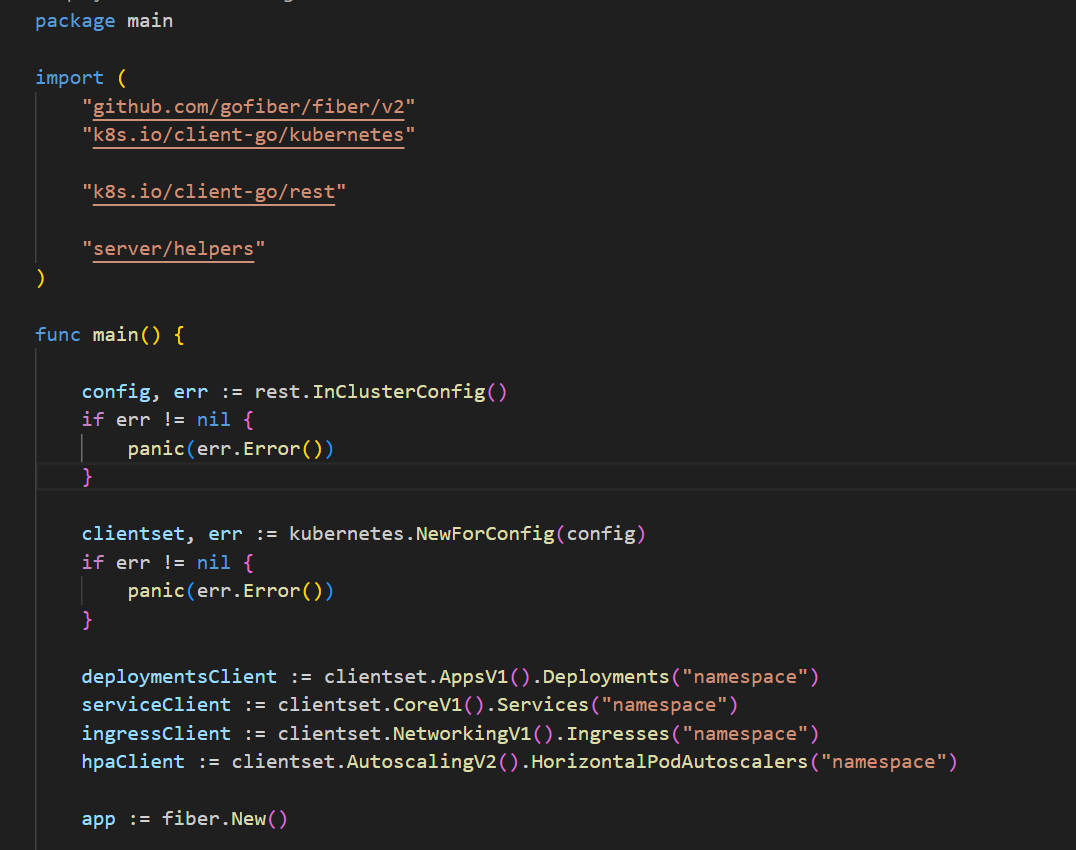
As evident, errors are represented as values in this context, signifying the absence of harmless uncaught exceptions that might disrupt the program. The representation of errors as values necessitates handling errors when they arise.
Additionally, a new instance of a Fiber App has been created at this juncture, accompanied by the establishment of Kubernetes clients essential for subsequent Kubernetes-related operations.
Route Handlers
In this section, a route correlated with a specific HTTP method is defined, and information is extracted from the HTTP request body. If one was curious about the inner workings of the helpers module and a desired to delve into the detailed implementation of these components and methods, access to the complete application code in the linked GitHub repository is provided below:
https://github.com/iolap-blog/mlops.

Goroutines
This demonstrates the utilization of goroutines to execute various tasks concurrently. Essentially, a function is invoked with the 'go' keyword, and Golang manages the concurrent execution process.
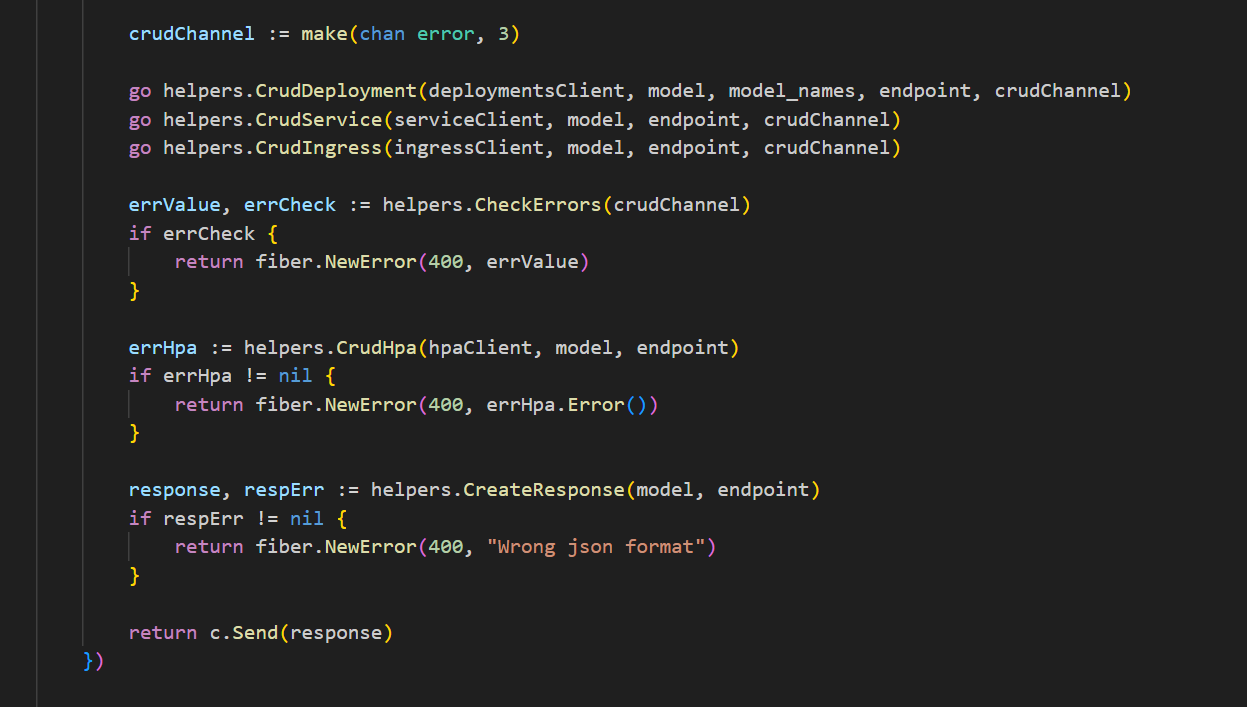
A channel has been established and passed to each goroutine to facilitate intercommunication among them. Channels serve as conduits through which values can be sent and received from both ends. By defining the channel's capacity, it implies that when the capacity limit is reached, the channel will block the goroutine until another goroutine reads a value from it.
This method offers a straightforward and efficient means to achieve parallelism and/or concurrency. In cases where multiple CPUs are available, genuine parallelism can be achieved seamlessly. Ultimately, a response is generated and dispatched to the client.
Kubernetes Integration
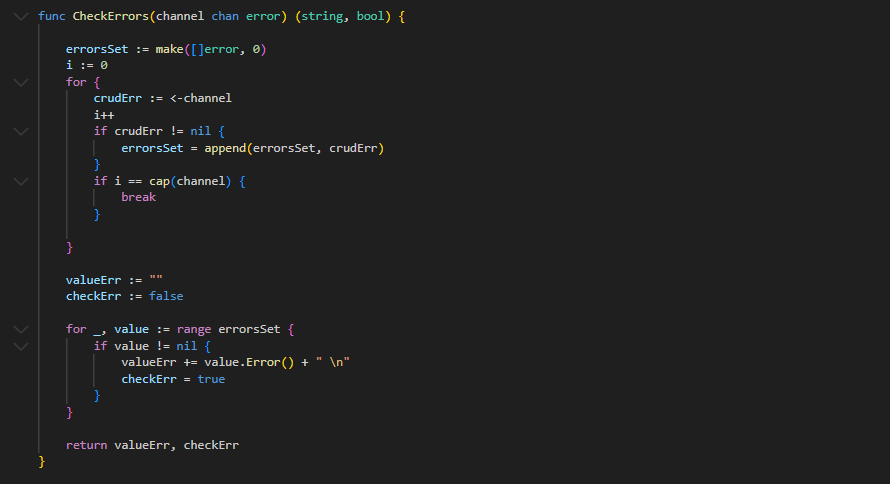
An illustration showcasing how a Kubernetes Deployment can be created using the Golang Client, along with the deployment process, is depicted below.


The utilization of channels is evident in the code to gather potential errors. Subsequently, an iteration over these errors is conducted to wait for the resources until their creation. This process is feasible due to the blocking nature of receiving values from channels in this context. Thus, it ensures the wait until either all resources are successfully created or until encountering errors that can be managed later in the code.
Docker Image
Finally, this is the method employed to generate a Docker image encapsulating the application, culminating in an image size of merely 31 MB. Once more, it showcases a swift and efficient approach to deploying a microservice onto a Kubernetes Cluster.

Conclusion
Why Kubernetes
Kubernetes is an excellent choice for building an ML Platform due to its versatility. It allows the creation of highly customized services, offering more flexibility than specific cloud providers. Additionally, Kubernetes is cost-efficient as it avoids the higher expenses associated with certain vendor platforms. Its cloud-agnostic nature means you can deploy your cluster anywhere—across any cloud or on-premises—avoiding vendor lock-in, which is vital for future planning.
The uncertainty surrounding the choice of a cloud provider and the desire to avoid long-term lock-in further justify the use of Kubernetes. It grants complete control over microservices and overall architectural objectives.
Why Go
The use of Golang presents considerable advantages in this context, especially since Kubernetes itself is written in Golang. However, Python should not be overlooked. It's ideal for building ML models, rapid prototyping, and situations where its use is most logical. On the other hand, Golang is better suited for specific tasks where it surpasses Python, or for larger-scale projects. The key lies in discerning when to use a particular language and understanding the trade-offs involved.
Why iOLAP
Want to deploy and manage ML models at scale, automate and orchestrate your machine learning lifecycle, distribute your machine learning processes? We can provide end-to-end machine learning solutions, design, build, and manage reproducible, testable, and evolvable ML software. Don’t hesitate to contact us, we can help you drive your business forward.